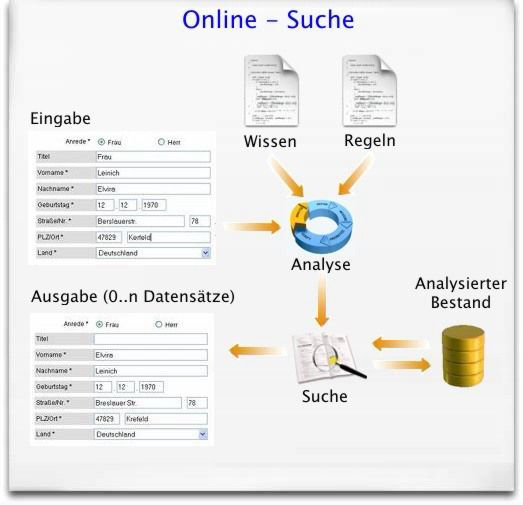
Ein Kernproblem in den heutigen Applikationen und Systemen sind die oft mangelhaften Suchmechanismen, d. h. entweder werden nicht alle gesuchten Datensätze gefunden (Underkill) oder aber die Suche liefert zu viele nicht interessierende Ergebnisse (Overkill), durch die dann umständlich und zeitintensiv geblättert werden muss.
Merkmal der fehlertoleranten, intelligenten und treffsicheren Online-Suche mit der AS MearchBox ist die Suche mit einigen wenigen, oft auch verstümmelten, fehlerbehafteten aber ähnlichen Eingaben, die dann die in Frage kommenden Datensätze aus dem Bestand der Höhe der Ähnlichkeit nach sortiert liefert.
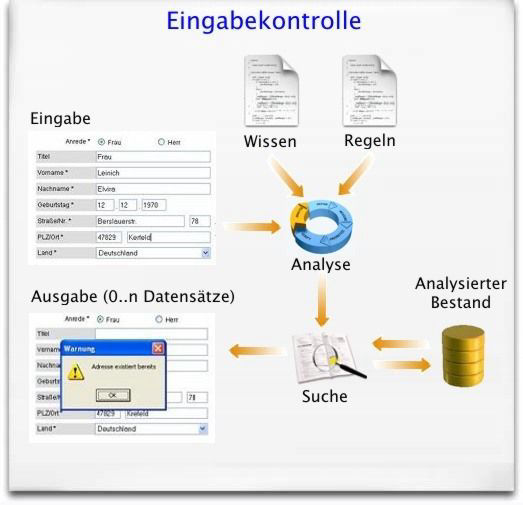
Hier handelt es sich um eine der Online-Suche sehr ähnliche Anwendung einer Identifikationssoftware. Ziel ist es, vor der Speicherung einer Neueingabe diese zuerst im Bestand zu suchen und vor möglichen, bereits vorhandenen Einträgen der gleichen Person oder Organisation zu warnen, um online die Erzeugung neuer Dubletten zu verhindern. Es handelt sich also bei der hier beschriebenen Eingabekontrolle um einen Online-Dublettencheck.
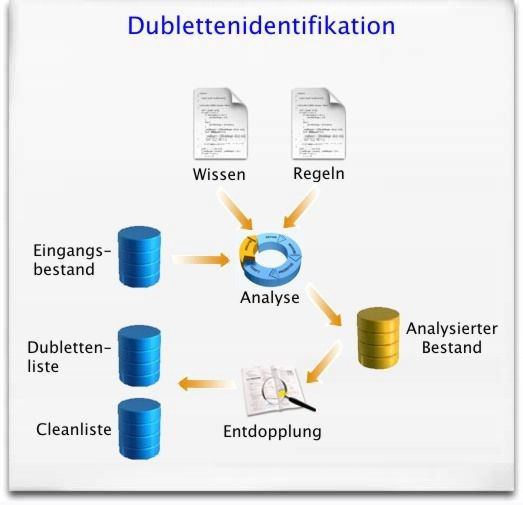
Bei einer Dublettenidentifikation geht es darum, alle sicheren und potentiellen Dubletten innerhalb eines Bestandes zu identifizieren. Dabei wird prinzipiell jeder Datensatz mit den jeweils anderen sukzessive verglichen und bei genügend hoher, frei definierbarer Ähnlichkeit das entsprechende Vergleichspaar in eine Ergebnisdatei oder Tabelle geschrieben. Neben dieser paarweisen Sicht werden auch automatisch Gruppensichten (d. h. alle miteinander korrelierenden Datensätze erhalten die gleiche Gruppennummer), Eyecatcher- (Kopfdublette einer Dublettengruppe, die nach verschiedenen Verfahren ermittelt werden kann) und Cleanliste (alle Kopfdubletten zzgl. der Einzelgruppen, also ein dublettenfreier Ergebnisbestand) generiert, so dass eine Analyse und Integration der Ergebnisse optimal unterstützt wird.

Unter einem Referenzmatch verstehen wir den Vergleich von zwei bzw. mehr Adressbeständen untereinander, d. h. es werden neben den in jedem einzelnen Bestand enthaltenen Dubletten auch diejenigen Datensätze ermittelt, die im anderen Bestand ebenfalls vorhanden sind. Der klassische Referenzmatch wird z. B. benötigt, wenn Sie Ihren eigenen Datenbestand gegen externe Adressen (z. B. Robinsonliste, Umzugsdatei, Neuadressen, Bestände mit Bonitätsinformationen, Nixies, etc.) zum Zwecke der Datenanreicherung bzw. des Datenimports abgleichen möchten. Ein anderes Beispiel wäre der Vergleich von Adressen, die intern in unterschiedlichen Abteilungen und/oder Systemen gepflegt werden und zwischen denen keine Verbindungen bestehen.
Aufbau eines standardisierten Analysebestands unter Einbeziehung unserer riesigen Wissens- und Regeldatenbank

AS Address Solutions GmbH
Kastanienweg 15
52223 Stolberg/Rhld.