
Die Arbeitsweise der AS OriginBox unterscheidet sich von anderen Verfahren, mit denen der sprachliche und kulturelle Hintergrund einer Person auf Basis des Namens identifiziert wird, im wesentlichen dadurch, dass der Vor- und Nachname und evtl. weitere Namenselemente zunächst analysiert, strukturiert und anschließend separat bestimmten Sprach- und/oder Kulturkreisen zugeordnet werden, um schließlich als Kombination aller Einzelinformationen ein Gesamtergebnis für die mögliche Zugehörigkeit zu generieren.
Herkömmliche Verfahren, die beispielswiese auf bestimmten Endungen von Namen basieren oder einfach in einem Namen insgesamt nach bestimmten Worten, Zeichenketten oder auch nach Namen aus einer definierten Vor-/Nachnamensliste suchen, können die Treffsicherheit der AS OriginBox nicht bieten.
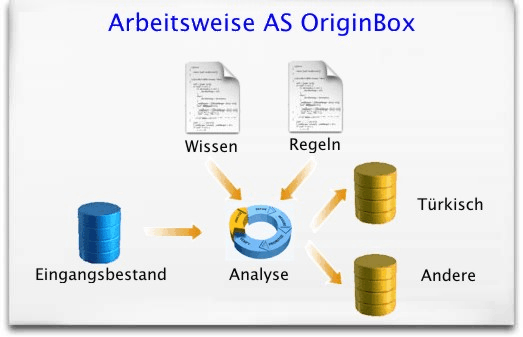
Generell kann man die Arbeitsweise der AS OriginBox in drei Hauptschritte unterteilen. Zuerst wird ein eingegebener Name in eine korrekte Struktur überführt, so dass Vorname, Nachname, Präfix, etc. isoliert zur Verfügung stehen. Danach werden Zuordnungen des Vor- und Nachnamen zu möglichen Sprach- und Kulturkreisen separat ermittelt und schließlich wird aus der Kombination von Vor- und Nachname auf Basis eines Regelwerks das Sprach- und/oder Kulturkennzeichen für den Gesamtnamen bestimmt.
Der Vorgang ist in der Grafik veranschaulicht, bei dem exemplarisch Namen aus dem türkischen Sprachraum identifiziert werden sollen.
Die AS OriginBox kann in Online-Prozessen und in Batch-Prozessen eingesetzt werden. Derzeit werden dabei folgende Sprach- und Kulturräume unterstützt:
Asiatisch (z. B. Vietnam, China, Japan, Thailand, etc.)
Afrikanisch (nicht arabischer Sprach- und Kulturraum Afrikas)
Spanisch/Portugiesisch (z. B. Spanien, Portugal, Südamerika)
Ex-UdSSR (z. B. Russland, Litauen, Georgien, Estland, Armenien, Ukraine, etc.)
Ex-Jugoslawisch (z. B. Serbien, Bosnien und Herzegowina, Kroatien, Montenegro, Slowenien, Mazedonien)
Ex-Tschecheslowakei (tschechischer und slowakischer Sprach- und Kulturkreis)
Polnisch (Polen, teilweise auch Russland, Litauen, Belarus, Ukraine)
Osteuropäisch (z. B. osteuropäischer Sprach- und Kulturraum, sofern nicht näher spezifiziert oder in eine der anderen Gruppen eingeordnet)
Skandinavisch (z. B. Schweden, Norwegen, Dänemark, Finnland, aber auch Island, etc.)
Arabisch (z. B. die arabischen Staaten Nordafrikas, Tunesien, Marokko, Algerien, etc.)
BeNeLux (Niederlande, Belgien, Luxemburg)
Italienisch (Italien, Schweiz)
Deutsch (Deutschland, Österreich, Schweiz)
Französisch (z. B. Frankreich, Schweiz, Kanada, teilweise aber auch Belgien)
Englisch (z. B. England, Schottland, Irland, USA, Australien)
Türkisch (z. B. Türkei inkl. des kurdischen Sprach- und Kulturraums, teilweise Zypern, Bulgarien)
Griechisch (z. B. Griechenland, teilweise Zypern, Mazedonien, Albanien)
Bevor einzelne Sprach- und Kulturräume beschrieben werden, muss an dieser Stelle ausdrücklich betont werden, dass es bei der Ermittlung des Sprach- und Kulturrumes eines Namens nicht um die Ermittlung seiner ethnischen Herkunft geht. Besonders deutlich wird dies beispielsweise bei der Kategorie Ex-Jugoslawien: Hier wird nicht zwischen Slowenen, Mazedonieren, Kroaten, Bosniaken oder Serben unterschieden, da dies aus Datenschutzgründen bedenklich wäre. Zum anderen wäre eine solche Zuordnung aber auch im Sinne der eigentlichen Bestimmung überhaupt nicht förderlich, da in den Jahren des Bestehens Jugoslawiens längst eine erhebliche Vermischung all dieser Kreise stattgefunden hat. Aus diesem Grunde denken wir auch, dass der inzwischen etablierte Begriff des „Ethno-Marketings“ äußerst unglücklich und missverständlich getroffen wurde. Der durchaus positive Grundgedanke der hinter dieser Art des Marketings steht, nämlich die zielgerichtete Kommunikation mit einem bestimmten Sprach- und Kulturraum unter Berücksichtigung dessen ganz spezieller Bedürfnisse, wird hierbei oft durch den faden Beigeschmack des Wortes Ethno in den Hintergrund gerückt.
Unter dem Begriff "Osteuropa" haben wir bei unserer AS OriginBox alle ehemaligen Staaten des Warschauer Pakts zusammengefasst, für die keine differenzierte Sprache und/oder Kultur identifiziert werden kann.
- Alle Staaten der ehemaligen UdSSR, z. B. Russland, Litauen, Georgien, Estland, Lettland, Moldawien, etc. die sich durchaus von einander unterscheiden. Das Problem hierbei sind auch die asiatischen Länder der ehemaligen Sowjetunion, die natürlich durchaus Überschneidungen mit asiatischen Herkünften aufweisen können.
- Ex-Jugoslawien ist heute unterteilt in Slowenien, Mazedonien, Serbien & Montenegro (Rest-Jugoslawien), Bosnien-Herzegowina und Kroatien. Insbesondere in Bosnien-Herzegowina ist der Anteil der Moslems (den sogenannten Bosniaken) mit 38% sehr hoch, so dass sich hier auch eine ganze Reihe von Namen finden, die Ähnlichkeiten mit den arabischen bzw. auch den türkischen Namen aufweisen (allerdings gibt es dennoch einige Trennmerkmale, die dann zu der Einordnung dieser Namen zu Osteuropa und nicht den türkischen oder arabischen Sprachraum geführt haben).
- Albanien und hier insbesondere auch die Kosovo-Albaner weisen wiederum recht eigenständige Namen auf, die sich von den jugoslawischen oder russischen Namen weitestgehend unterscheiden.
- Auch Armenien gehört in der AS OriginBox derzeit zu Osteuropa, wenn auch die armenischen Namen deutliche Unterschiede zu den anderen, osteuropäischen Ländern aufweisen.
Insgesamt gesehen wird der wachsenden Bedeutung Osteuropas in künftigen Versionen der AS OriginBox mehr Bedeutung zugeordnet, so dass dann der Sprach- und Kulturraum detaillierter bestimmt werden kann. Erste Tests zeigen einen zu erwartenden Qualitätsstand wie z. B. bei den Türken (d. h. die einem osteuropäischen Land fälschlicherweise zugeordneten Namen erreichen die gleichen prozentualen Anteile). In dieser Gruppe fällt weiter auf, dass viele ziemlich eindeutig zu Osteuropa zu zählende Namen auf Grund eklatanter Schreibfehler und der unterschiedlichen Umsetzung der kyrillischen Schreibweisen zu nicht erkannten Nachnamen führten. Oft sind jedoch wegen der Problematik der Umsetzung der kyrillischen Schriftzeichen auch unterschiedliche Schreibweisen des gleichen Namens im Umlauf, z. B. "Woronin" oder "Voronin".
Unter dem Begriff „türkischstämmiger Name“ verstehen wir Namen aus dem türkischen Sprach- und Kulturraum, also natürlich auch die vielen kurdischen Namen. Es wird also keinerlei Eingrenzung auf die vielfältigen ethnischen Gruppen in der Türkei vorgenommen. Von den ca. 10,5-11% nicht deutschstämmigen Mitbürgern sind ca. 3,0% Türken. Somit ist diese Zielgruppe, auch auf Basis ihrer immer mehr wachsenden Kaufkraft (ca. 17 Milliarden Euro pro Jahr), eine beliebte Zielgruppe. Aus diesem Grunde haben wir der korrekten Identifizierung des türkisch/kuridischen Sprach- und Kulturraums besonderes Gewicht verliehen, was oft sehr schwer ist, da diese Namen für das ungeübte Auge oft große Ähnlichkeiten mit z. B. griechischen, arabischen und bosnischen Namen aufweisen. Geringfügige Änderungen der Schreibweisen bei den oft für Deutsche ungewohnten Namen führen leider häufig dazu, dass die tatsächliche, türkische Zugehörigkeit nicht mehr zu ermitteln ist. Beispielsweise gibt es im Türkischen viele Namen die auf "man" enden, z. B. "Özman", "Süleyman", etc., die oft mit zwei "n" am Ende geschrieben werden und dann nicht mehr zu erkennen sind. Insbesondere führen oft folgende Probleme dazu, dass die Identifizierung nicht möglich ist:
- Sehr viele Namen deuten sehr wohl auf einen türkischen Hintergrund hin, dies ist allerdings durch eine große Anzahl Schreibfehler in Vor- und Nachnamen nicht mehr erkennbar. Beispielsweise gibt es falsch geschriebene Namen wie "Süleymann", "Atamann", "Dikmann", die mit einem "n" geschrieben sehr wohl dem türkischen Sprach- und Kulturraum zuzuordnen wären. Überhaupt lassen sich unzählige Schreibfehler sehr einfach damit erklären, das hier deutsche Personen versucht haben, Namen aus anderen Sprachräumen aufzunehmen.
- Ein weiteres Problem mit derselben Ursache wie oben gibt es häufig bei der fälschlichen Vertauschung von Vor- und Nachnamen. Viele türkische Vornamen (z. B. "Süleyman", "Goekhan", "Bülent" klingen für Nicht-Türken nach Nachnamen, während türkische Nachnamen (z. B. "Kara", "Ibis", etc.) oft für Vornamen gehalten werden. Dadurch entstehen viele weitere Probleme, da der Namen durch eine solche Vertauschung letztendlich verstümmelt wird.
- Es gibt einige typische Merkmale für türkische Namen, wie z. B. das türkische Vornamen praktisch nie auf "d" enden und fast nie ein "j" enthalten. Die meisten Namen (z. B. "Ahmet", "Mohammet", etc.) kommen jedoch im arabischen Sprach- und Kulturgebiet sehr wohl auch mit einem "d" am Ende vor, so dass ein "Ahmed Cengiz" sicherlich ein Türke sein dürfte, allerdings mit falschgeschriebenem Vornamen ("Ahmet" statt "Ahmed" müsste es heißen). Viele Vornamen, die ein "y" enthalten (z. B. "Sabriye", "Fetiye", etc.) gibt es im ex-jugoslawischem Sprachgebiet (z. B. in Bosnien) mit einem "j" ("Sabrije", "Fetije"), das gleiche kommt auch bei den Nachnamen vor (z. B. "Bayram" und "Bajram"). Diese wahrscheinlichen Türken, die jedoch massive Schreibfehler beinhalten, können von uns natürlich nicht mit dem türkischen Sprachkennzeichen herausgegeben werden. Ein Mailing an diese Personen dürfte auch eher peinlich sein, da die falsche Schreibweise auf Verärgerung stoßen kann.
- Lese- oder Scanfehler der Namen sorgen oft für Probleme, da die dann resultierenden Namen entweder gar nicht existieren oder aber einem anderen Kulturkreis angehören. Ein gutes Beispiel hierfür sind häufige Umsetzungen von einem "y" in ein "g".
Dies sind nur einige der häufigsten Problemursachen. Ziel unserer Sprach- und Kulturraumbestimmung ist jedoch eine möglichst geringe Fehlerquote bei der Bestimmung, die im Normalfall <1% sein dürfte.
Die Klasse der arabischen Namen versteht sich mehr als eine Klasse der muslimischen Länder der arabischen aber auch der nordafrikanischen Welt. Hier ist besonders die korrekte Abgrenzung gegenüber den sehr ähnlichen aber dennoch unterschiedlichen Namen des türkischen und bosnischen Sprach- und Kulturraums wichtig.
Zu der Gruppe der asiatischen Namen zählen in allererster Linie Chinesen, Vietnamesen, Koreaner (Süd- und Nordkorea) und Japaner.
Beim Aufruf der AS OriginBox wird immer ein Landesparameter mit übergeben, der die vermutete bzw. erwartete Zugehörigkeit der Namen repräsentiert. Dies ist wichtig für Namen, die eigentlich typisch deutsch, englisch und französisch sein können, z.B. "Robert Martin". Hier ist sicherlich "Robert" ein deutscher, englischer und französischer Vorname, genauso ist "Martin" ein in Deutschland, Großbritannien und Frankreich (und auch noch in anderen Ländern) existierender Nachname. Wenn nun als Landesparameter Deutschland eingestellt wurde, wird als Sprach- und Kulturraum für diesen Namen "German" ermittelt, da dies der Erwartungshaltung entspricht. Selbstverständlich gehören auch österreichische und schweizerische Namen zu dieser Gruppe.

AS Address Solutions GmbH
Kastanienweg 15
52223 Stolberg/Rhld.